摘要:
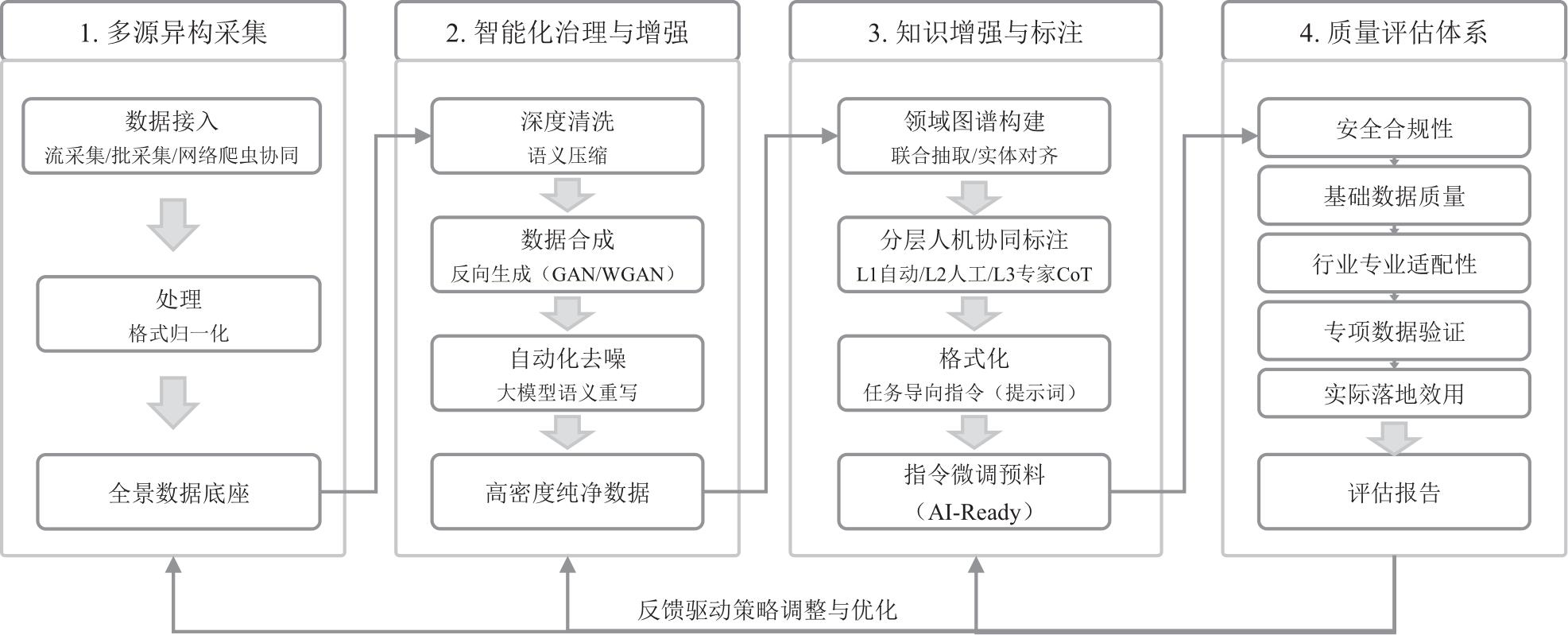
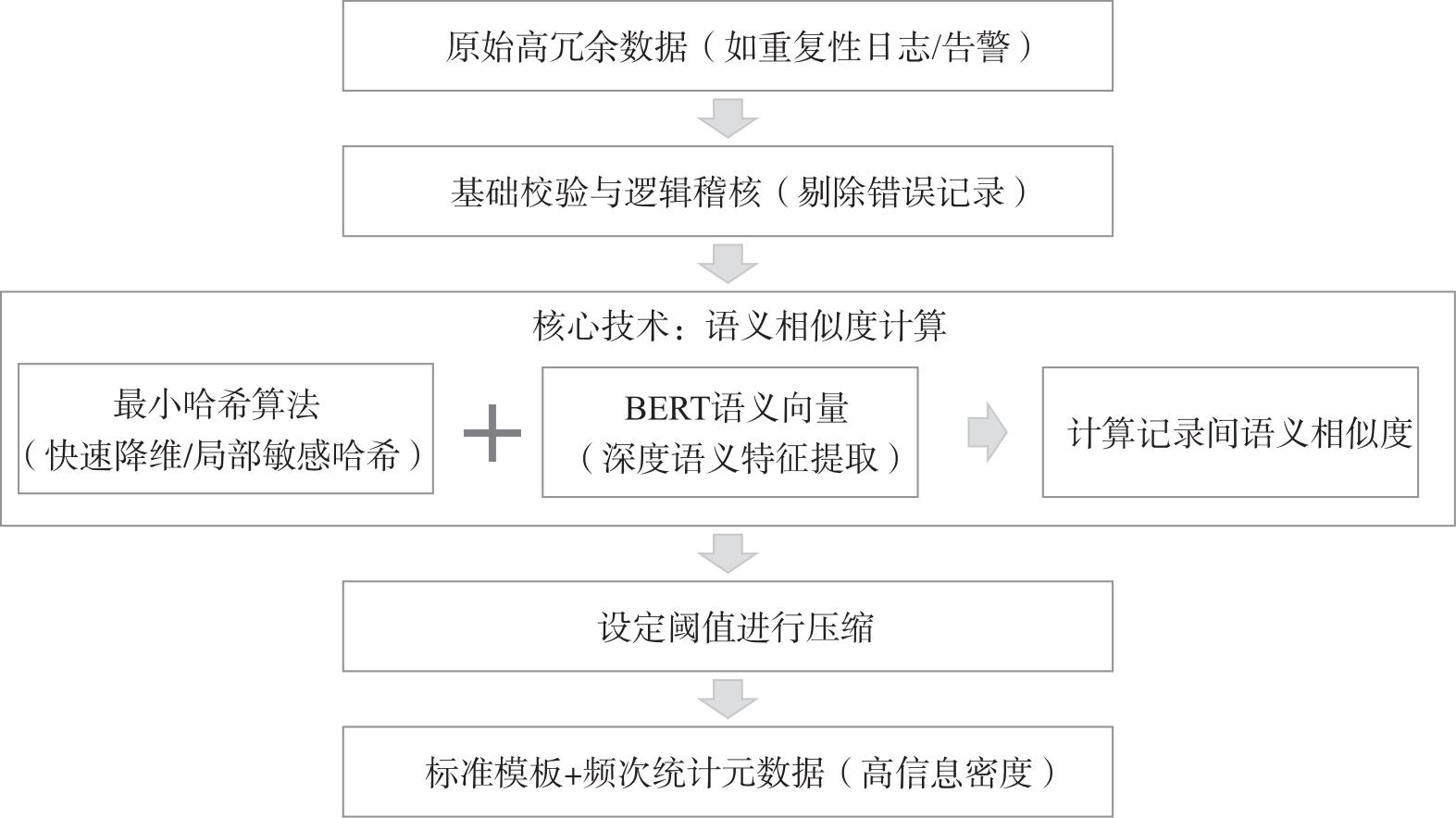
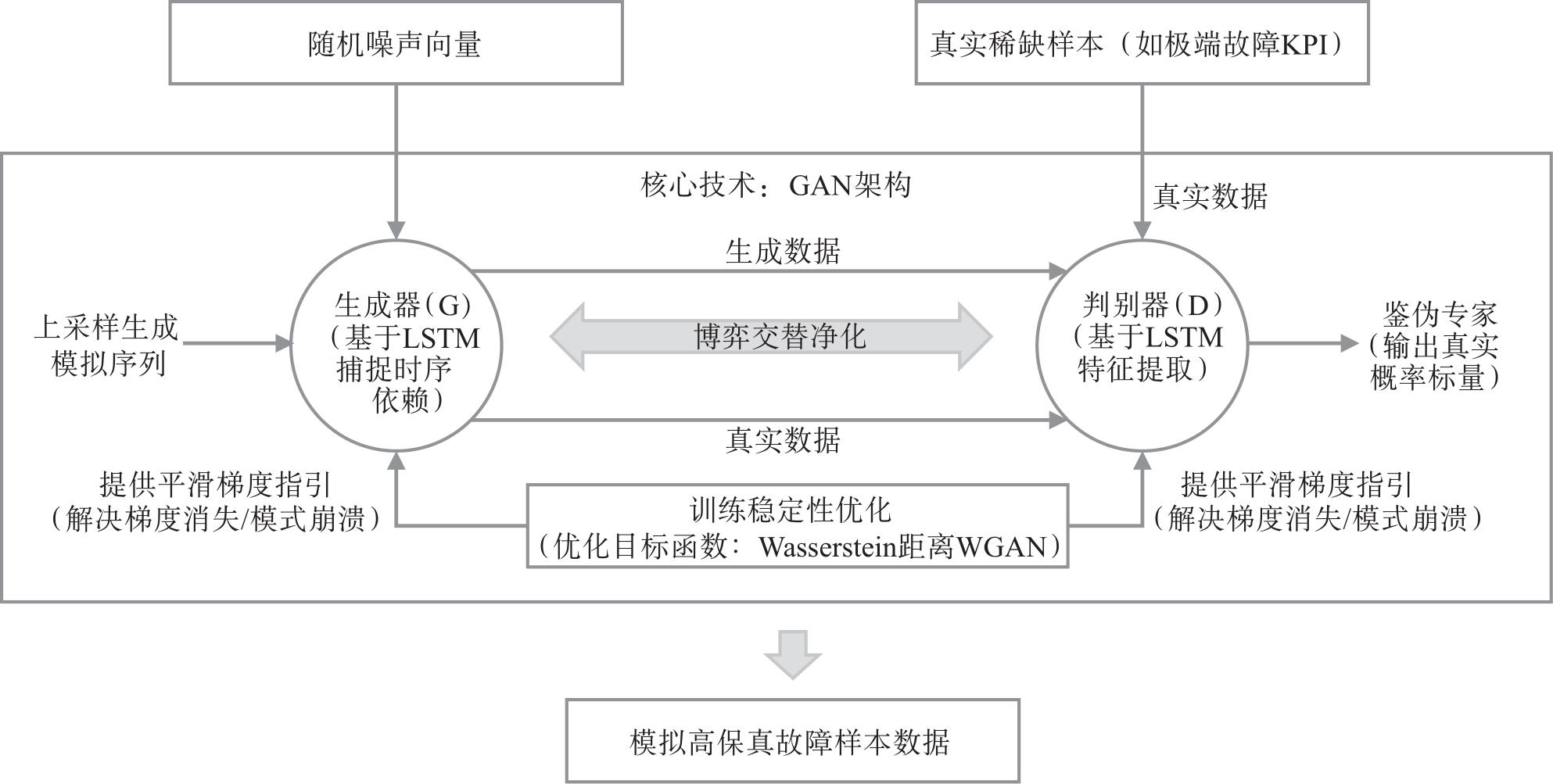
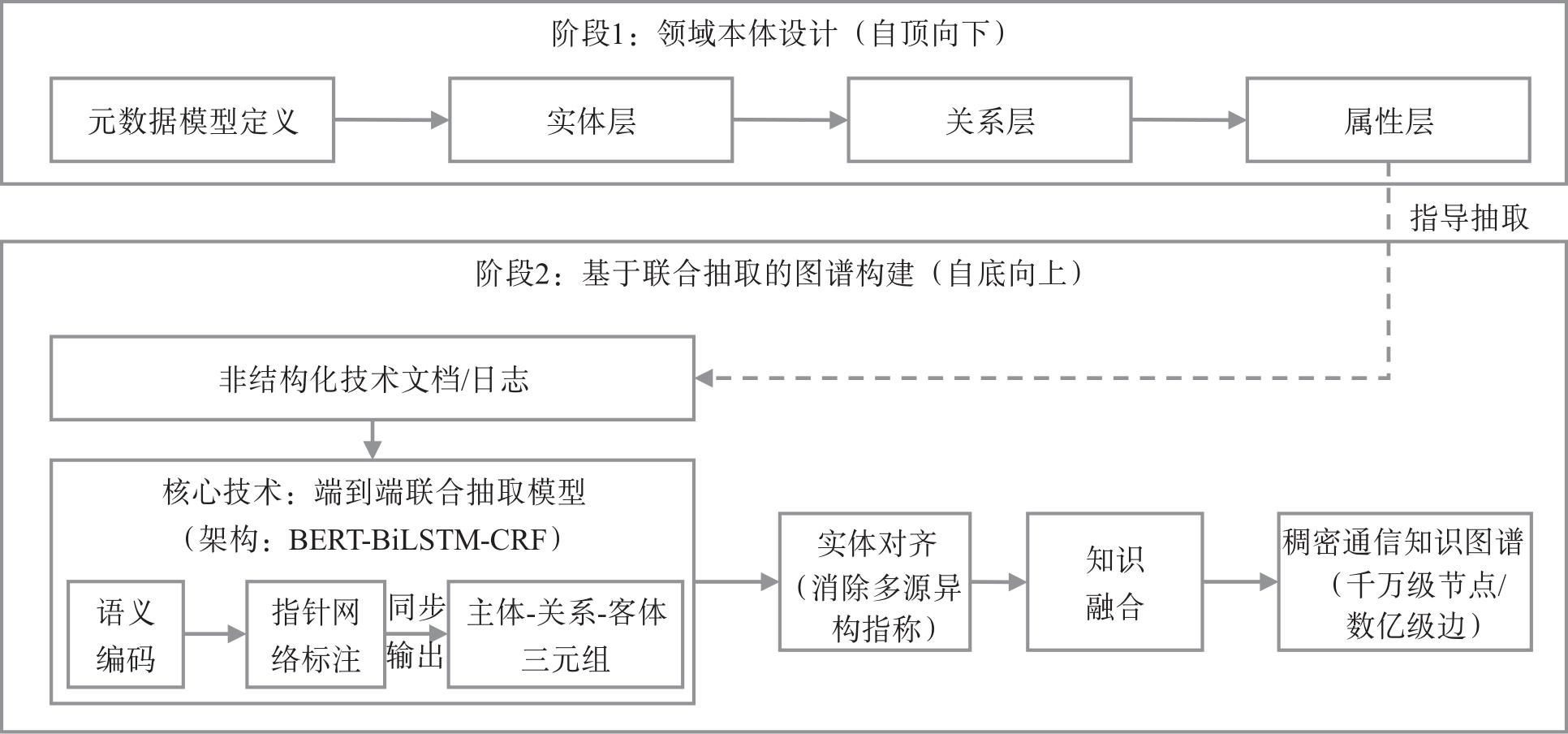
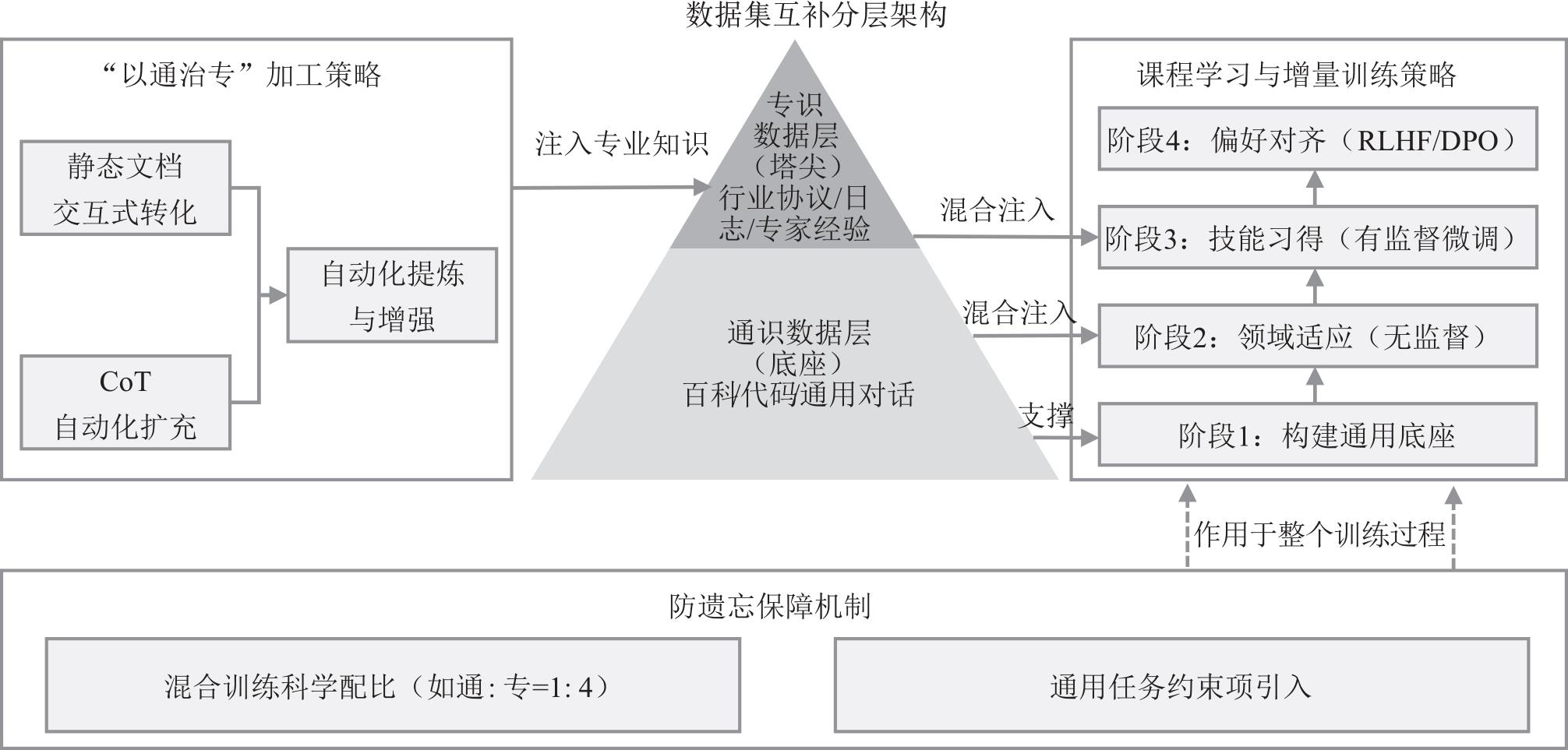
随着生成式人工智能技术的快速演进,数据质量已成为制约行业大模型性能的核心瓶颈。电信运营商掌握ZB量级跨域数据,具备训练垂直大模型的先天资源优势,然而原始通信数据普遍存在多源异构、冗余度高、长尾样本稀缺等问题,直接应用于模型训练效果有限。基于此,系统地提出“采集—治理—标注—评估”高质量数据集构建方法,涵盖深度语义压缩、基于沃瑟斯坦生成对抗网络与长短期记忆网络的长尾数据合成、领域本体构建与人机协同标注等关键技术;同时,设计通识与专识数据协同机制,有效缓解行业微调过程中的“灾难性遗忘”问题。实践证明,该方法行之有效,可为通信行业高质量数据集构建提供参考。
中图分类号:
肖文彬, 李雨霏, 黄倚霄, 马闻达. 面向大模型训练的通信行业高质量数据集构建方法与实践[J]. 信息通信技术与政策, 2026, 52(5): 41-49.
XIAO Wenbin, LI Yufei, HUANG Yixiao, MA Wenda. Construction methods and practice of high-quality datasets for telecommunications large model training[J]. Information and Communications Technology and Policy, 2026, 52(5): 41-49.