| [1] |
栗蔚, 张博圣, 孙松林, 等. 算力互联网架构: 基于熵平衡支持算力资源跨域互联的下一代网络架构[J]. 通信学报, 2025, 46(9)1-16.
|
| [2] |
张慧敏. DeepSeek-R1是怎样炼成的?[J]. 深圳大学学报(理工版), 2025, 42(2):226-232.
|
| [3] |
HU E J, SHEN Y, WALLIS P, et al. LoRA: low-rank adaptation of large language models[J]. arXiv Preprint, arXiv:2106.09685,2021.
|
| [4] |
DETTMERS T, PAGNONI A, HOLTZMAN A, et al. QLoRA:efficient finetuning of quantized llms[J]. arXiv Preprint, arXiv: 2305.14314x1, 2023.
|
| [5] |
XIA M, ZHONG Z, CHEN D. Sheared LLaMA: accelerating language model pre-training via structured pruning[J]. arXiv Preprint, arXiv:2310.06694, 2023.
|
| [6] |
CHEN L, LI S, ZOU X. AlpaGasus: training a better alpaca with fewer data[J]. arXiv Preprint, arXiv:2307.08701v5, 2024.
|
| [7] |
SHOEYBI M, PATWARY M, PURI R, et al. Megatron-LM:training multi-billion parameter language models using model parallelism[C]//Proceedings of SC20: International Conference for High Performance Computing, Networking, Storage and Analysis.IEEE Press, 2020:1-15.
|
| [8] |
RAJBHANDARI S, RASLEY J, RUWASE O, et al. ZeRO:memory optimizations toward training trillion parameter models[C]//Proceedings of SC20: International Conference for High Performance Computing, Networking, Storage and Analysis.IEEE Press, 2020:1-15.
|
| [9] |
MICIKEVICIUS P, NARANG S, ALBEN J, et al. Mixed precision training[J]. arXiv Preprint, arXiv:1710. 03740, 2018.
|
| [10] |
HOULSBY N, GIURGIU A, JASTRZEBSKI S, et al. Parameter-Efficient transfer learning for NLP[C]// Proceedings of the 36th International Conference on Machine Learning. Long Beach: PMLR Press, 2019:2790-2799.
|
| [11] |
LESTER B, AL-RFOU R, CONSTANT N. The power of scale for parameter-efficient prompt tuning[C]// Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Punta Cana: Association for Computational Linguistics, 2021:3045-3059.
|
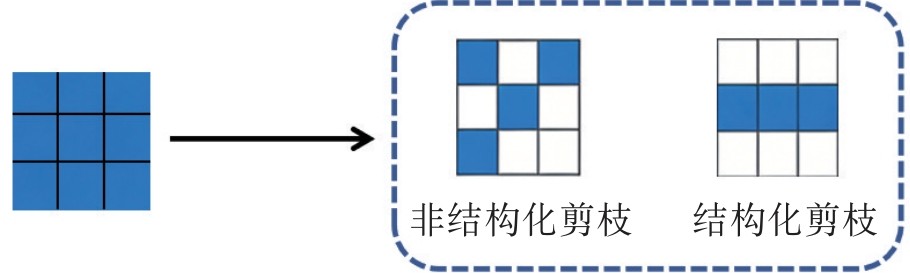
| [12] |
BLALOCK D, ORTIZ J G M, FRANKLE J, et al. What is the state of neural network pruning?[J]. arXiv Preprint, arXiv:2003.03033, 2020.
|
| [13] |
FRANTAR E, ASHKBOOS S, HOEFLER T, et al. GPTQ: accurate post-training quantization for generative pre-trained transformers[J]. arXiv Preprint, arXiv:2210.17323v2, 2023.
|
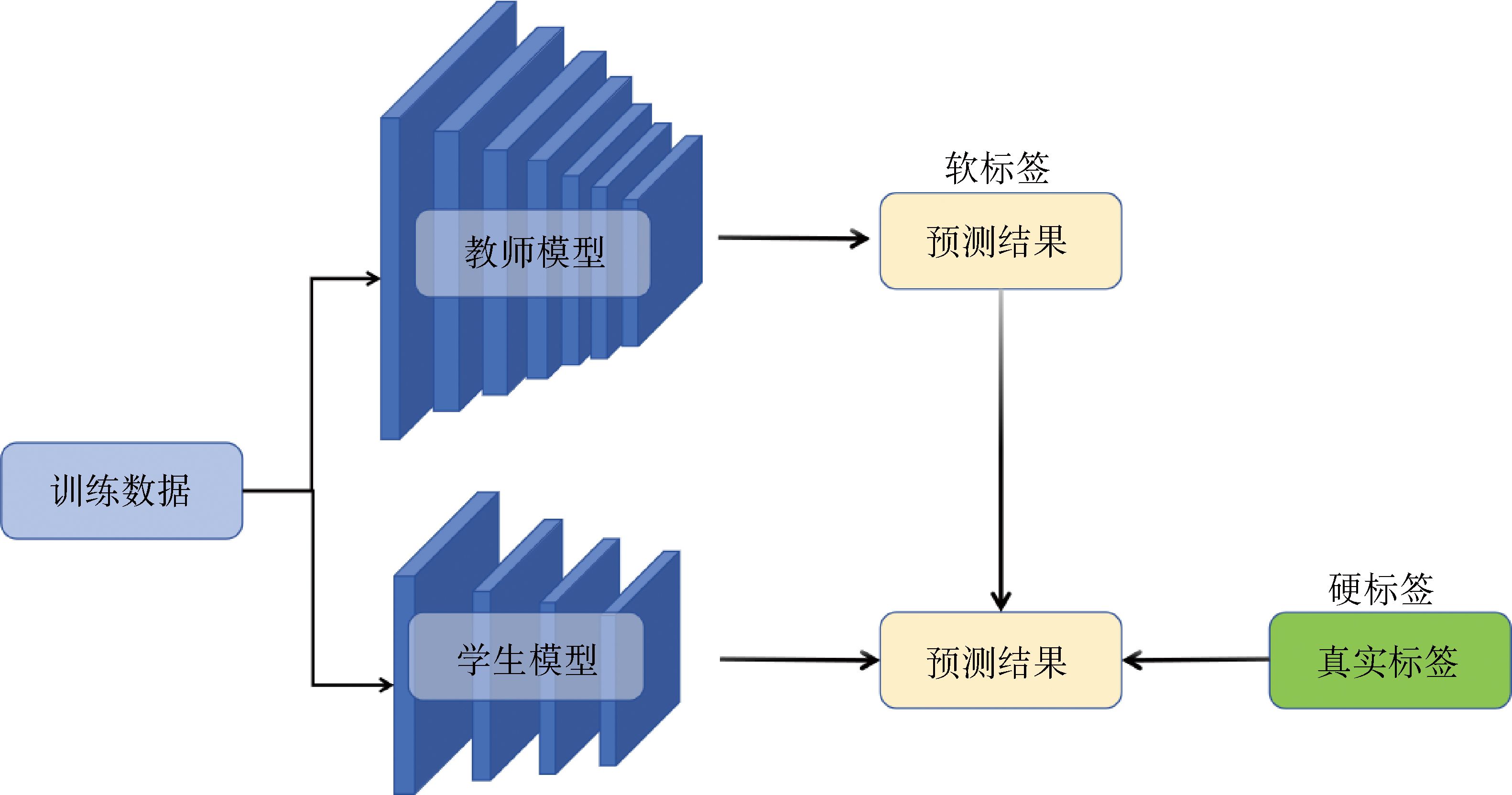
| [14] |
邵仁荣, 刘宇昂, 张伟, 等. 深度学习中知识蒸馏研究综述[J]. 计算机学报, 2022, 45(8):1638-1673.
|
| [15] |
LUO J, WU B, LUO X, et al. A Survey on efficient large language model training: from data-centric perspectives[C]// Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics. Bangkok: Association for Computational Linguistics, 2025:30904-30920.
|
| [16] |
REIMERS N, GUREVYCH I. Sentence-BERT:sentence embeddings using Siamese BERT-networks[C]// Proceedings of 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. New York: Association for Computational Linguistics, 2019:3982-3992.
|
| [17] |
BRODER A Z. On the resemblance and containment of documents[C]// Proceedings of the Conference on Compression and Complexity of Sequences. Salerno: IEEE Computer Society, 1997:21-29.
|
| [18] |
WANG Y, KORDI Y, MISHRA S, et al. Self-Instruct: aligning language models with self-generated instructions[C]// Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics. Toronto: Association for Computational Linguistics, 2023:8658-8668.
|
| [19] |
DAI D, DENG C Q, ZHAO C G, et al. DeepSeekMoE: towards ultimate expert specialization in mixture-of-experts language models[J]. arXiv Preprint, arXiv: 2401.06066v1, 2023.
|
| [20] |
EVCI U, GALE T, MENICK J, et al. Rigging thelottery: making all tickets winners[C]// Proceedings of the 37th International Conference on Machine Learning. Vienna: PMLR, 2020:2943-2952.
|