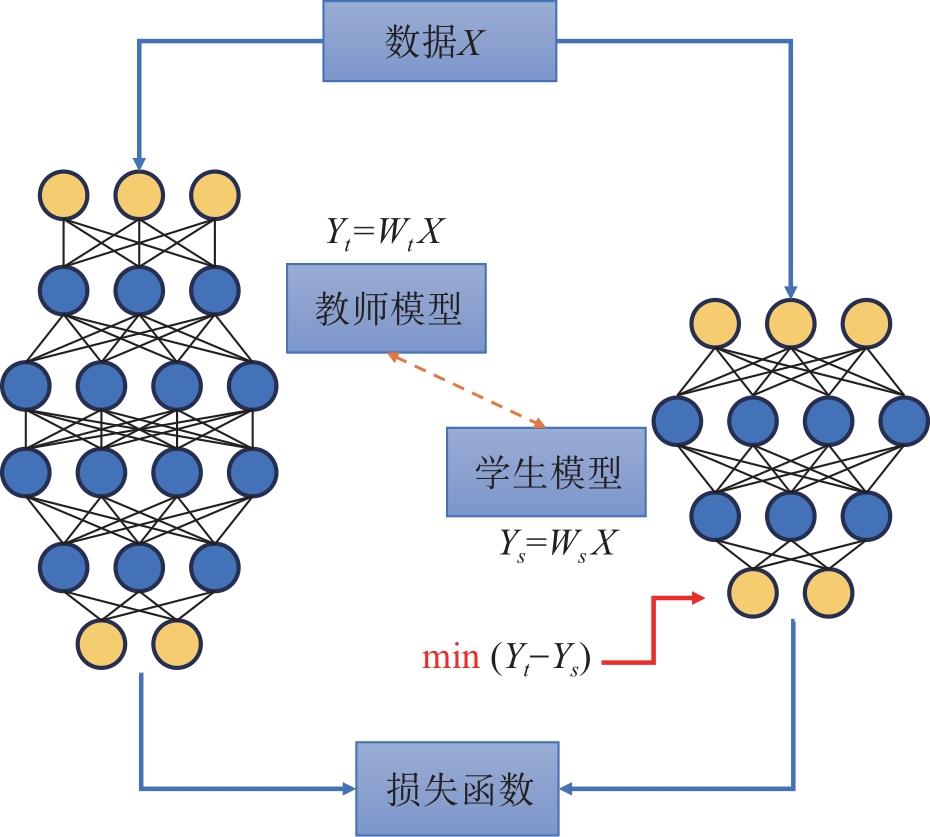
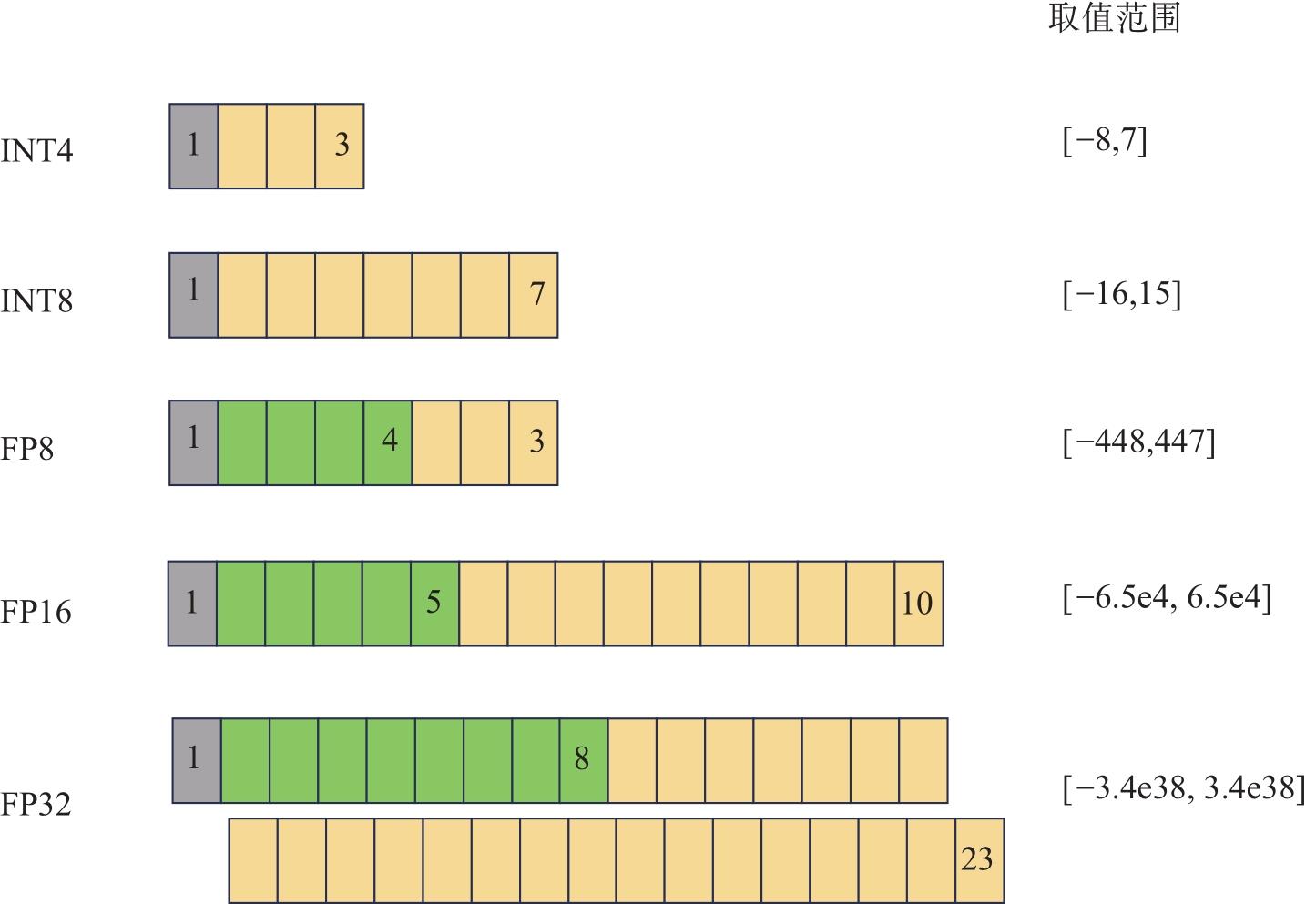
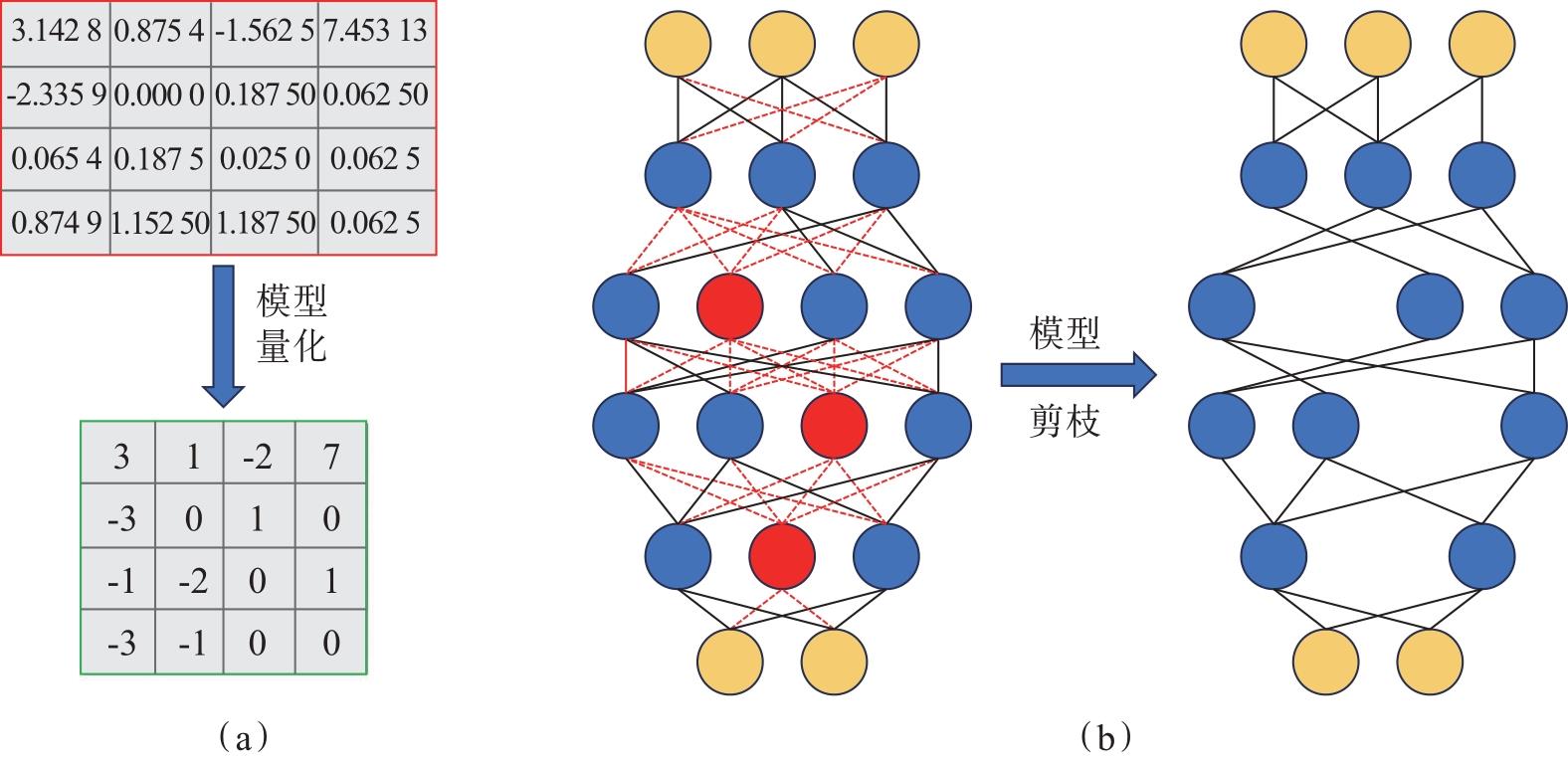
| [1] |
BROWN T, MANN B, RYDER N, et al. Language models are few-shot learners[C]//Proceedings of the 34th International Conference on Neural Information Processing Systems(NIPS’20). Red Hook: Curran Associates Inc., 2020, 33: 1877-1901.
|
| [2] |
中央网络安全和信息化委员会. “十四五”国家信息化规划[EB/OL], 2021[2025-04-22]. https://www.gov.cn/xinwen/2021-12/28/5664873/files/1760823a103e4d75ac681564fe481af4.pdf.
|
| [3] |
国家能源局. 国家能源局关于加快推进能源数字化智能化发展的若干意见[EB/OL]. (2023-03-28)[2025-04-22]. https://www.gov.cn/zhengce/zhengceku/2023-04/02/content_5749758.htm.
|
| [4] |
梁芳, 佟恬, 马贺荣, 等. 东数西算下算力网络发展分析[J]. 信息通信技术与政策, 2022, 48(11):79-83.
doi: 10.12267/j.issn.2096-5931.2022.11.010
|
| [5] |
Stanford University Human-Centered AI. Artificial intelligence index report 2023[R], 2023.
|
| [6] |
ZHOU Y, LIN X J, ZHANG X, et al. On the opportunities of green computing: a survey[J]. arXiv Preprint, arXiv:2311.00447, 2023.
|
| [7] |
ZOIE R C, MIHAELA R D, ALEXANDRU S. An analysis of the power usage effectiveness metric in data centers[C]//2017 5th International symposium on electrical and electronics engineering (ISEEE). Galati: IEEE, 2017:1-6.
|
| [8] |
PRICE D C, CLARK M A, BARSDELL B R, et al. Optimizing performance-per-watt on GPUs in high performance computing: temperature, frequency and voltage effects[J]. Computer Science-Research and Development, 2016, 31(4): 185-193.
|
| [9] |
陈巍. 大模型技术与产业分析[EB/OL]. 2024[2025-04-22]. https://www.zhihu.com/column/c_1607003152053755904.
|
| [10] |
PATEL J M. Introduction to common crawl datasets[M]// Getting structured data from the internet:running web crawlers/scrapers on a big data production scale. Berkeley: Apress, 2020: 277-324.
|
| [11] |
SUN Z, YU H, SONG X, et al. Mobilebert: a compact task-agnostic bert for resource-limited devices[J]. arXiv Preprint, arXiv:2004. 02984, 2020.
|
| [12] |
JIAO X, YIN Y, SHANG L, et al. Tinybert: distilling bert for natural language understanding[J]. arXiv Preprint, arXiv:1909.10351, 2019.
|
| [13] |
FEDUS W, ZOPH B, SHAZEER N. Switch transformers: scaling to trillion parameter models with simple and efficient sparsity[J]. Journal of Machine Learning Research, 2022, 23(120):1-39.
|
| [14] |
LIU H, LI Z, HALL D, et al. Sophia: a scalable stochastic second-order optimizer for language model pre-training[J]. arXiv Preprint, arXiv:2305.14342, 2023.
|
| [15] |
LIANG H, ZHANG S, SUN J, et al. Darts+: improved differentiable architecture search with early stopping[J]. arXiv Preprint, arXiv:1909.06035, 2019.
|
| [16] |
HARLAP A, NARAYANAN D, PHANISHAYEE A, et al. Pipedream: fast and efficient pipeline parallel dnn training[J]. arXiv Preprint, arXiv:1806.03377, 2018.
|
| [17] |
LIN Y, HAN S, MAO H, et al. Deep gradient compression: reducing the communication bandwidth for distributed training[J]. arXiv Preprint,arXiv:1712.01887, 2017.
|
| [18] |
TANG H, YU C, LIAN X, et al. Doublesqueeze: parallel stochastic gradient descent with double-pass error-compensated compression[C]// International Conference on Machine Learning. PMLR, 2019: 6155-6165.
|
| [19] |
LIN Z, COURBARIAUX M, MEMISEVIC R, et al. Neural networks with few multiplications[J]. arXiv Preprint, arXiv:1510.03009, 2015.
|
| [20] |
MICIKEVICIUS P, NARANG S, ALBEN J, et al. Mixed precision training[J]. arXiv Preprint, arXiv:1710.03740, 2017.
|
| [21] |
HAN S, MAO H, DALLY W J. Deep compression: compressing deep neural networks with pruning, trained quantization and huffman coding[J]. arXiv Preprint, arXiv:1510.00149, 2015.
|
| [22] |
WANG X, TANG Z, GUO J, et al. Empowering edge intelligence: a comprehensive survey on on-device ai models[J]. ACM Computing Surveys, 2025, 57(9):39.
|
| [23] |
TAN M, LE Q. Efficientnet: rethinking model scaling for convolutional neural networks[C]//International conference on machine learning. PMLR,2019: 6105-6114.
|
| [24] |
GHOSH S K, RAHA A, RAGHUNATHAN V. Energy-efficient approximate edge inference systems[J]. ACM Transactions on Embedded Computing Systems, 2023, 22(4): 1-50.
|
| [25] |
任杰, 高岭, 于佳龙, 等. 面向边缘设备的高能效深度学习任务调度策略[J]. 计算机学报, 2020, 43(3): 440-452.
|
| [26] |
ZHAI Y, JIANG C, WANG L, et al. Bytetransformer:a high-performance transformer boosted for variable-length inputs[C]//2023 IEEE International Parallel and Distributed Processing Symposium (IPDPS). Atlanta: IEEE, 2023: 344-355.
|
| [27] |
WU B, LIU S, ZHONG Y, et al. Loongserve:efficiently serving long-context large language models with elastic sequence parallelism[C]//Proceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles(SOSP’24). New York: Association for Computing Machinery, 2024: 640-654.
|
| [28] |
SONG Y, MI Z, XIE H, et al. Powerinfer: fast large language model serving with a consumer-grade GPU[C]//Proceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles. New York: Association for Computing Machinery, 2024: 590-606.
|
| [29] |
XU M, ZHU M, LIU Y, et al. Deepcache: principled cache for mobile deep vision[C]//Proceedings of the 24th annual international conference on mobile computing and networking. New York: Association for Computing Machinery, 2018:129-144.
|