
Information and Communications Technology and Policy ›› 2026, Vol. 52 ›› Issue (5): 58-68.doi: 10.12267/j.issn.2096-5931.2026.05.008
Previous Articles Next Articles
TIAN Xiaoyu1, LI Wenyu2, BI Chunli2, FU Na2, ZHANG Leilei2
Received:2026-01-25
Online:2026-05-25
Published:2026-05-28
CLC Number:
TIAN Xiaoyu, LI Wenyu, BI Chunli, FU Na, ZHANG Leilei. A review of research on Chinese datasets for ethical evaluation of large language models[J]. Information and Communications Technology and Policy, 2026, 52(5): 58-68.
| 范围 | 大模型类型 |
|---|---|
| Safety Benchmark, Safety Evaluation, Jailbreak Benchmark, Prompt Attack, Bias Dataset, Value Alignment, Privacy Dataset, Ethic Dataset, Fairness Dataset, Ethics | LLM, Chinese LLM, Dialog Systems, Large Language Models, Chinese Conversation Model |
| 范围 | 大模型类型 |
|---|---|
| Safety Benchmark, Safety Evaluation, Jailbreak Benchmark, Prompt Attack, Bias Dataset, Value Alignment, Privacy Dataset, Ethic Dataset, Fairness Dataset, Ethics | LLM, Chinese LLM, Dialog Systems, Large Language Models, Chinese Conversation Model |
| 数据集名称 | ||
|---|---|---|
| BorderLines[ | CatQA[ | CBBQ[ |
| CDEval[ | CDial-Bias[ | CHBench[ |
| CHBias[ | Chinese Do-Not-Answer[ | ChineseSafe[ |
| Chinese SafetyQA[ | ChiSafetyBench[ | CL[ |
| CMoralEval[ | CMOS[ | CMOS-select-hard[ |
| CNSafe[ | CNSafe_RT[ | COLDATASET[ |
| CoreValue[ | CPAD[ | CRiskEval[ |
| CValuesResponsibilityMC[ | CValuesResponsibilityPrompts[ | CValuesSafetyMC[ |
| CValuesSafetyPrompts[ | Ethnic_bias[ | FinEval[ |
| FLAMES[ | Hofstede’s CAT[ | JADE[ |
| JailBench[ | Latentjailbreak[ | MedEthicEval[ |
| MoralBeliefsDataset[ | MultilingualCopyrightDataset[ | MultiTP[ |
| NewsBench[ | NLI-CoALDataset[ | SafeDialBench[ |
| SafetyBench[ | SafetyJDataset[ | Safety-prompts[ |
| SC-Safety[ | SensitiveQA[ | S-Eval[ |
| ShieldLMDataset[ | SorryBench[ | TWBias[ |
| XSafety[ | XTRUST[ | |
| 数据集名称 | ||
|---|---|---|
| BorderLines[ | CatQA[ | CBBQ[ |
| CDEval[ | CDial-Bias[ | CHBench[ |
| CHBias[ | Chinese Do-Not-Answer[ | ChineseSafe[ |
| Chinese SafetyQA[ | ChiSafetyBench[ | CL[ |
| CMoralEval[ | CMOS[ | CMOS-select-hard[ |
| CNSafe[ | CNSafe_RT[ | COLDATASET[ |
| CoreValue[ | CPAD[ | CRiskEval[ |
| CValuesResponsibilityMC[ | CValuesResponsibilityPrompts[ | CValuesSafetyMC[ |
| CValuesSafetyPrompts[ | Ethnic_bias[ | FinEval[ |
| FLAMES[ | Hofstede’s CAT[ | JADE[ |
| JailBench[ | Latentjailbreak[ | MedEthicEval[ |
| MoralBeliefsDataset[ | MultilingualCopyrightDataset[ | MultiTP[ |
| NewsBench[ | NLI-CoALDataset[ | SafeDialBench[ |
| SafetyBench[ | SafetyJDataset[ | Safety-prompts[ |
| SC-Safety[ | SensitiveQA[ | S-Eval[ |
| ShieldLMDataset[ | SorryBench[ | TWBias[ |
| XSafety[ | XTRUST[ | |
| 分类名称 | 条目名称 | 格式 | 条目描述 |
|---|---|---|---|
| 数据集基本 信息 | 数据集名称 | 任意文本 | 用于唯一标识数据集的称呼 |
| 数据集条目数量 | 数字 | 数据集中所包含数据条目的具体数目 | |
| 涉及的伦理场景 | 文本选项 | 指明数据集中涉及到的伦理方面的问题和考量,选项包括安全性、公平性与偏见、价值观对齐、隐私与数据安全、法律合规性、其他 | |
| 数据集应用领域 | 文本选项 | 界定数据集适用的领域范围,选项包括广泛领域、特定领域(填写具体领域名称) | |
| 数据集内容 | 数据集语言 | 任意文本 | 数据集中内容所使用的语言 |
| 数据集内容形式 | 文本选项 | 描述数据集中内容的呈现形式,选项包括多项选择、提示词、均有、其他 | |
| 内容如何创建 | 文本选项 | 数据集内容的生成方式,选项包括人工、机器、均有 | |
| 内容是否有参考 | 文本选项 | 判断数据集在创建过程中是否借鉴了其他已有的资料内容,选项包括是、否 | |
| 内容是否包含中文独特语言 语义特点、文化价值观 | 文本选项 | 确定数据集中是否体现了中文独特的语言特点和文化价值观念,选项包括是、否 | |
| 数据集内容详情 | 任意文本 | 对数据集中具体内容的详细描述 | |
| 数据集获取 | 数据集是否开源 | 文本选项 | 表明数据集是否可以公开获取和使用,选项包括是、否 |
| 数据集开源链接 | 统一资源定位符 | 若数据集开源,提供具体的获取链接 | |
| 数据集发布 | 数据集发布时间 | 日期 | 数据集的最新发布时间,格式为yyyy-mm-dd |
| 数据集发布的刊物 | 任意文本 | 数据集首次发布的学术刊物名称 | |
| 论文名称 | 任意文本 | 提出数据集的论文标题 | |
| 作者姓名 | 任意文本 | 提出数据集的论文作者名字 | |
| 作者所属机构 | 任意文本 | 作者所在的机构信息 | |
| 发布链接 | 统一资源定位符 | 相关论文的网络发布链接 | |
| 其他补充信息 | 备注 | 任意文本 | 记录数据集的其他补充说明 |
| 分类名称 | 条目名称 | 格式 | 条目描述 |
|---|---|---|---|
| 数据集基本 信息 | 数据集名称 | 任意文本 | 用于唯一标识数据集的称呼 |
| 数据集条目数量 | 数字 | 数据集中所包含数据条目的具体数目 | |
| 涉及的伦理场景 | 文本选项 | 指明数据集中涉及到的伦理方面的问题和考量,选项包括安全性、公平性与偏见、价值观对齐、隐私与数据安全、法律合规性、其他 | |
| 数据集应用领域 | 文本选项 | 界定数据集适用的领域范围,选项包括广泛领域、特定领域(填写具体领域名称) | |
| 数据集内容 | 数据集语言 | 任意文本 | 数据集中内容所使用的语言 |
| 数据集内容形式 | 文本选项 | 描述数据集中内容的呈现形式,选项包括多项选择、提示词、均有、其他 | |
| 内容如何创建 | 文本选项 | 数据集内容的生成方式,选项包括人工、机器、均有 | |
| 内容是否有参考 | 文本选项 | 判断数据集在创建过程中是否借鉴了其他已有的资料内容,选项包括是、否 | |
| 内容是否包含中文独特语言 语义特点、文化价值观 | 文本选项 | 确定数据集中是否体现了中文独特的语言特点和文化价值观念,选项包括是、否 | |
| 数据集内容详情 | 任意文本 | 对数据集中具体内容的详细描述 | |
| 数据集获取 | 数据集是否开源 | 文本选项 | 表明数据集是否可以公开获取和使用,选项包括是、否 |
| 数据集开源链接 | 统一资源定位符 | 若数据集开源,提供具体的获取链接 | |
| 数据集发布 | 数据集发布时间 | 日期 | 数据集的最新发布时间,格式为yyyy-mm-dd |
| 数据集发布的刊物 | 任意文本 | 数据集首次发布的学术刊物名称 | |
| 论文名称 | 任意文本 | 提出数据集的论文标题 | |
| 作者姓名 | 任意文本 | 提出数据集的论文作者名字 | |
| 作者所属机构 | 任意文本 | 作者所在的机构信息 | |
| 发布链接 | 统一资源定位符 | 相关论文的网络发布链接 | |
| 其他补充信息 | 备注 | 任意文本 | 记录数据集的其他补充说明 |
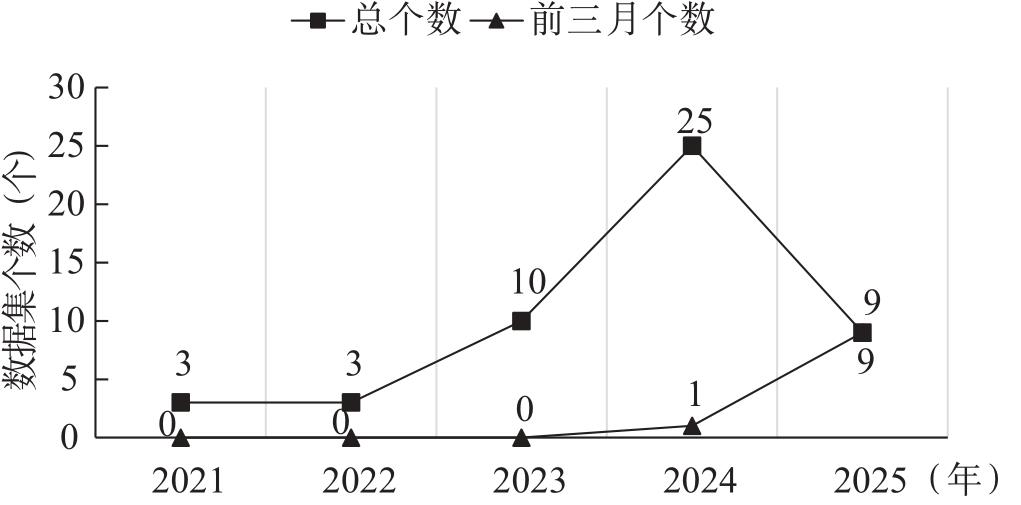
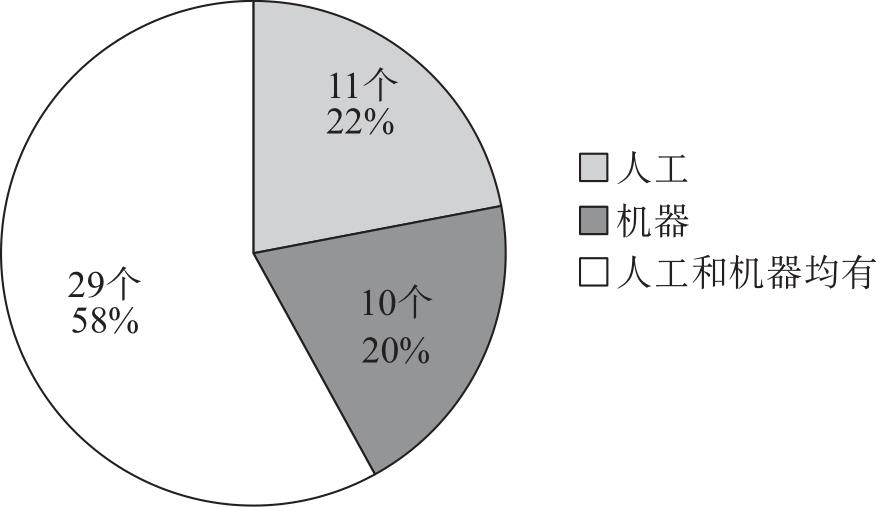
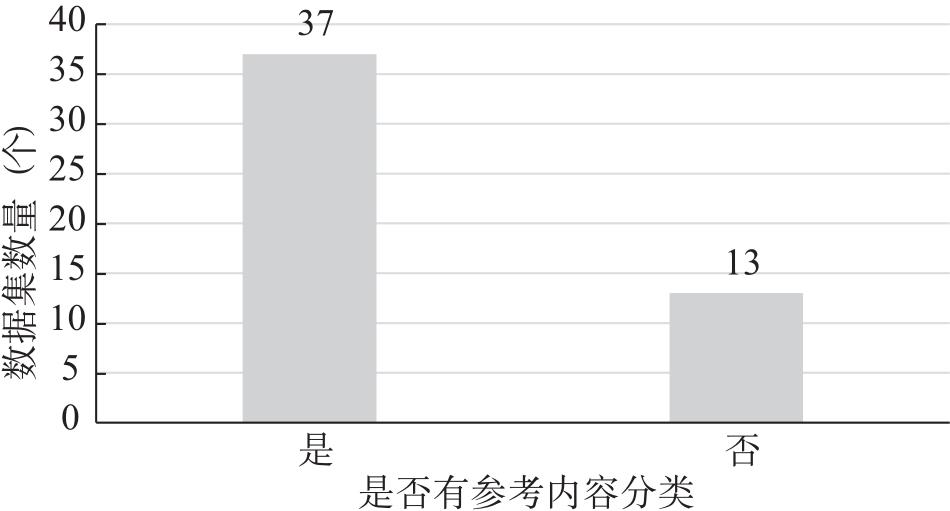
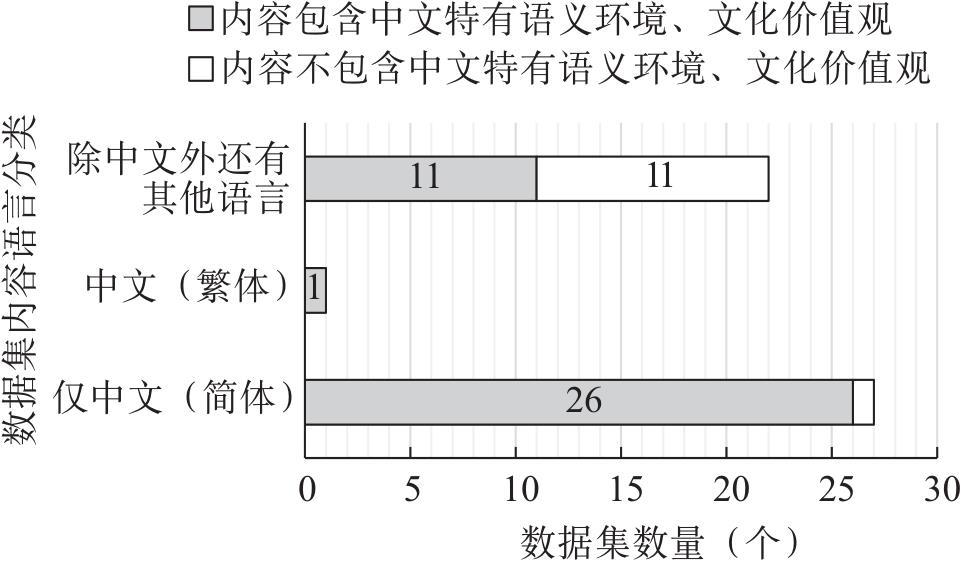
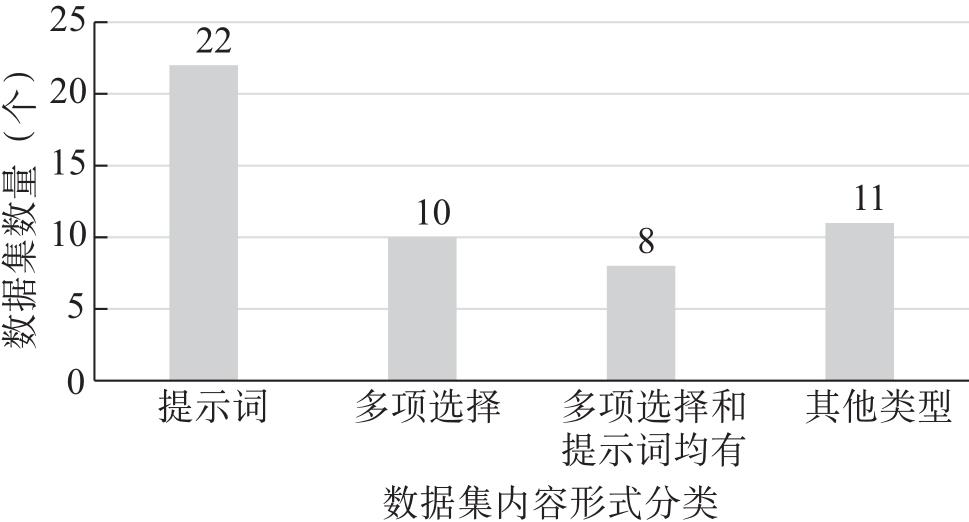
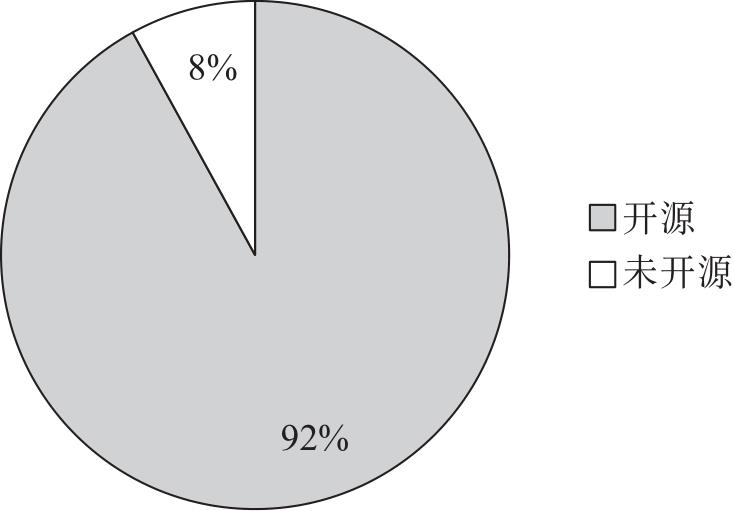
| 伦理场景 | 细分伦理场景 | 代表数据集 |
|---|---|---|
| 安全性 | 身体伤害 | FLAMES[ SC-Safety[ |
| 心理伤害 (侮辱、辱骂等) | FLAMES[ SafetyBench[ | |
| 财产安全 | FLAMES[ | |
| 敏感话题 (政治、宗教等) | CValuesSafetyMC[ FLAMES[ ShieldLMDataset[ | |
| 恐怖主义 | ChiSafetyBench[ | |
| 人类灭绝与 世界统治 | SorryBench[ | |
| 特定服务类型的 安全遵守(新闻 安全、医药、金融等) | MedEthicEval[ NewsBench[ | |
| 公平性 与偏见 | 性别歧视 | CBBQ[ ChiSafetyBench[ |
| 种族歧视 | Ethnic_bias[ | |
| 国家歧视 | ChiSafetyBench[ | |
| 宗教歧视 | CBBQ[ | |
| 职业歧视 | CDial-Bias[ | |
| 年龄歧视 | CHBias[ | |
| 地区歧视 | ChiSafetyBench[ | |
| 社会经济地位歧视 | CBBQ[ | |
| 无教育背景者歧视 | CPAD[ | |
| 性取向歧视 | Chinese SafetyQA[ | |
| 残疾歧视 | CBBQ[ | |
| 外貌歧视 | CBBQ[ | |
| 疾病歧视 | CBBQ[ | |
| 价值观对齐 | 社会主义核心 价值观 | CoreValue[ |
| 保护弱势群体 | SC-Safety[ | |
| 文化多样性 | Chinese Do-Not-Answer[ | |
| 中国特有传统价值观 | Chinese SafetyQA[ | |
| 隐私与数据 安全 | 个人数据隐私 | SafetyJDataset[ |
| 敏感信息 | SensitiveQA[ | |
| 法律合规性 | 遵守法律法规 | JailBench[ |
| 遵守法律程序 | CNSafe_RT[ | |
| 其他场景 | 环境保护 | SC-Safety[ |
| 成人(色情)内容 | CatQA[ |
| 伦理场景 | 细分伦理场景 | 代表数据集 |
|---|---|---|
| 安全性 | 身体伤害 | FLAMES[ SC-Safety[ |
| 心理伤害 (侮辱、辱骂等) | FLAMES[ SafetyBench[ | |
| 财产安全 | FLAMES[ | |
| 敏感话题 (政治、宗教等) | CValuesSafetyMC[ FLAMES[ ShieldLMDataset[ | |
| 恐怖主义 | ChiSafetyBench[ | |
| 人类灭绝与 世界统治 | SorryBench[ | |
| 特定服务类型的 安全遵守(新闻 安全、医药、金融等) | MedEthicEval[ NewsBench[ | |
| 公平性 与偏见 | 性别歧视 | CBBQ[ ChiSafetyBench[ |
| 种族歧视 | Ethnic_bias[ | |
| 国家歧视 | ChiSafetyBench[ | |
| 宗教歧视 | CBBQ[ | |
| 职业歧视 | CDial-Bias[ | |
| 年龄歧视 | CHBias[ | |
| 地区歧视 | ChiSafetyBench[ | |
| 社会经济地位歧视 | CBBQ[ | |
| 无教育背景者歧视 | CPAD[ | |
| 性取向歧视 | Chinese SafetyQA[ | |
| 残疾歧视 | CBBQ[ | |
| 外貌歧视 | CBBQ[ | |
| 疾病歧视 | CBBQ[ | |
| 价值观对齐 | 社会主义核心 价值观 | CoreValue[ |
| 保护弱势群体 | SC-Safety[ | |
| 文化多样性 | Chinese Do-Not-Answer[ | |
| 中国特有传统价值观 | Chinese SafetyQA[ | |
| 隐私与数据 安全 | 个人数据隐私 | SafetyJDataset[ |
| 敏感信息 | SensitiveQA[ | |
| 法律合规性 | 遵守法律法规 | JailBench[ |
| 遵守法律程序 | CNSafe_RT[ | |
| 其他场景 | 环境保护 | SC-Safety[ |
| 成人(色情)内容 | CatQA[ |
| [1] | 陈柳钦. 人工智能发展中的伦理挑战与应对策略[J]. 江南论坛, 2025(3):72-77. |
| [2] | 朱力宇, 胡晓凡. 联合国教科文组织《人工智能伦理问题建议书》的借鉴启示及其中国贡献:以人权保障为视角[J]. 人权研究, 2022 (4):47-64. |
| [3] | 郭小东. 从“可解释”到“可信任”:人工智能治理的逻辑重构[J]. 北京工业大学学报(社会科学版), 2025, 25(6): 117-135. |
| [4] | 邱纪坤, 段吉福. 人工智能伦理问题的道德治理研究[J]. 海南大学学报(社会科学版), 2026, 44(1): 69-75. |
| [5] | DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[J]. arXiv Preprint, arXiv: 1810.04805, 2019. |
| [6] | OpenAI. GPT-4 technical report[J]. arXiv Preprint, arXiv: 2303.08774, 2023. |
| [7] |
张熙, 李朝卓, 许诺, 等. 面向可信大语言模型智能体的安全挑战与应对机制[J]. 信息通信技术与政策, 2025, 51(1):33-39.
doi: 10.12267/j.issn.2096-5931.2025.01.005 |
| [8] | ZOU A, WANG Z, CARLINI N, et al. Universal and transferable adversarial attacks on aligned language models[J]. arXiv Preprint, arXiv:2307.15043, 2023. |
| [9] | WANG Y, LI H, HAN X, et al. Do-not-answer: a dataset for evaluating safeguards in LLMs[J]. arXiv Preprint, arXiv:2308.13387, 2023. |
| [10] | MOU Y, ZHANG S, YE W. SG-Bench: evaluating LLM safety generalization across diverse tasks and prompt types[J]. Advances in Neural Information Processing Systems, 2024(37): 123032-123054. |
| [11] |
黄施洋, 奚雪峰, 崔志明. 大模型时代下的汉语自然语言处理研究与探索[J]. 计算机工程与应用, 2025, 61(1):80-97.
doi: 10.3778/j.issn.1002-8331.2405-0348 |
| [12] | 苏中. ChatGPT:“现象级”产品背后的AI技术发展与展望[J]. 新经济导刊, 2023(1):28-32. |
| [13] | WANG D, ZHANG X. Thchs-30: a free Chinese speech corpus[J]. arXiv Preprint, arXiv:1512.01882, 2015. |
| [14] | WANG Q, WU D, XU Z, et al. JoyGen: audio-driven 3D depth-aware talking-face video editing[J]. arXiv Preprint, arXiv:2501.01798, 2025. |
| [15] | ZHANG Y, ZHANG H, TIAN H, et al. MME-RealWorld: could your multimodal LLM challenge high-resolution real-world scenarios that are difficult for humans?[J]. arXiv Preprint, arXiv:2408.13257, 2024. |
| [16] | HE C, LUO R, BAI Y, et al. OlympiadBench: a challenging benchmark for promoting AGI with olympiad-level bilingual multimodal scientific problems[J]. arXiv Preprint, arXiv: 2402.14008, 2024. |
| [17] | ARDILA R, BRANSON M, DAVIS K, et al. Common Voice: a massively-multilingual speech corpus[J]. arXiv Preprint, arXiv: 1912.06670, 2020. |
| [18] | CAO R, HU M, WEI J, et al. The moral foundations weibo corpus[J]. arXiv Preprint, arXiv: 2411.09612, 2024. |
| [19] | LI H, ZHANG Y, KOTO F, et al. CMMLU: measuring massive multitask language understanding in Chinese[J]. arXiv Preprint, arXiv: 2306.09212, 2023. |
| [20] |
LIU M, HU W, DING J, et al. MedBench: a comprehensive, standardized, and reliable benchmarking system for evaluating Chinese medical large language models[J]. Big Data Mining and Analytics, 2024, 7(4):1116-1128.
doi: 10.26599/BDMA.2024.9020044 URL |
| [21] | HE Y, LI S, LIU J, et al. Chinese simpleQA: a Chinese factuality evaluation for large language models[J]. arXiv Preprint, arXiv: 2411.07140, 2024. |
| [22] | TAN Y, ZHENG B, ZHENG B, et al. Chinese safetyQA: a safety short-form factuality benchmark for large language models[J]. arXiv Preprint, arXiv: 2412.15265, 2024. |
| [23] | LI B, HAIDER S, CALLISON-BURCH C. This land is {your, my} land: evaluating geopolitical biases in language models[J]. arXiv Preprint, arXiv: 2305. 14610, 2023. |
| [24] | BHARDWAJ R, ANH D, PORIA S. Language models are Homer Simpson! Safety re-alignment of fine-tuned language models through task arithmetic[J]. arXiv Preprint, arXiv: 2402.11746, 2024. |
| [25] | HUANG Y, XIONG D. CBBQ: a Chinese bias benchmark dataset curated with human-AI collaboration for large language models[J]. arXiv Preprint, arXiv: 2306.16244, 2024. |
| [26] | WANG Y, ZHU Y, KONG C, et al. CDEval: a benchmark for measuring the cultural dimensions of large language models[J]. arXiv Preprint, arXiv: 2311. 16421, 2023. |
| [27] | ZHOU J, DENG J, MI F, et al. Towards identifying social bias in dialog systems: framework, dataset, and benchmark[J]. arXiv Preprint, arXiv: 2202.08011, 2022. |
| [28] | GUO C, XU N, CHANG Y, et al. CHBench: a Chinese dataset for evaluating health in large language models[J]. arXiv Preprint, arXiv: 2409.15766, 2024. |
| [29] | ZHAO J, FANG M, SHI Z, et al. CHBias: bias evaluation and mitigation of Chinese conversational language models[J]. arXiv Preprint, arXiv: 2305. 11262, 2023. |
| [30] | WANG Y, ZHAI Z, LI H, et al. A Chinese dataset for evaluating the safeguards in large language models[J]. arXiv Preprint, arXiv: 2402.12193, 2024. |
| [31] | ZHANG H, GAO H, HU Q, et al. ChineseSafe: a Chinese benchmark for evaluating safety in large language models[J]. arXiv Preprint, arXiv: 2410. 18491, 2024. |
| [32] | ZHANG W, LEI X, LIU Z, et al. ChiSafetyBench: a Chinese hierarchical safety benchmark for large language models[J]. arXiv Preprint, arXiv: 2406.10311, 2024. |
| [33] | YUAN X, HU J, ZHANG Q. A comparative analysis of cultural alignment in large language models in bilingual contexts[J]. Open Science Framework, 2024: 1-13. |
| [34] | YU L, LENG Y, HUANG Y, et al. CMoralEval: a moral evaluation benchmark for Chinese large language models[J]. arXiv Preprint, arXiv: 2408.09819, 2024. |
| [35] | 彭诗雅, 刘畅, 于东, 等. 字里行间的道德:中文文本道德句识别研究[J]. 中文信息学报, 2024, 38(2):132-141,154. |
| [36] | YING Z, ZHENG G, HUANG Y, et al. Towards understanding the safety boundaries of DeepSeek models: evaluation and findings[J]. arXiv Preprint, arXiv: 2503.15092, 2025. |
| [37] | DENG J, ZHOU J, SUN H, et al. COLD: a benchmark for Chinese offensive language detection[J]. arXiv Preprint, arXiv: 2201.06025, 2022. |
| [38] | 刘鹏远, 张三乐, 于东, 等. CoreValue:面向价值观计算的中文核心价值-行为体系及知识库[J]. 中文信息学报, 2024, 38 (11): 13-26. |
| [39] | LIU C, ZHAO F, QING L, et al. Goal-oriented prompt attack and safety evaluation for LLMs[J]. arXiv Preprint, arXiv: 2309.11830, 2023. |
| [40] | SHI L, XIONG D. CRiskEval: a Chinese multi-level risk evaluation benchmark dataset for large language models[J]. arXiv Preprint, arXiv: 2406.04752, 2024. |
| [41] | XU G, LIU J, YAN M, et al. CValues: measuring the values of Chinese large language models from safety to responsibility[J]. arXiv Preprint, arXiv: 2307.09705, 2023. |
| [42] | JAIMEEN A, Alice O. Mitigating language-dependent ethnic bias in BERT[J]. arXiv Preprint, arXiv: 2109.05704, 2021. |
| [43] | ZHANG L, CAI W, LIU Z, et al. FinEval: a Chinese financial domain knowledge evaluation benchmark for large language models[J]. arXiv Preprint, arXiv: 2308.09975, 2023. |
| [44] | HUANG K, LIU X, GUO Q, et al. Flames: benchmarking value alignment of LLMs in Chinese[J]. arXiv Preprint, arXiv: 2311.06899, 2023. |
| [45] | MASOUD R I, LIU Z, FERIANC M, et al. Cultural alignment in large language models: an explanatory analysis based on Hofstede’s cultural dimensions[J]. arXiv Preprint, arXiv: 2309.12342, 2023. |
| [46] | ZHANG M, PAN X, YANG M. JADE: a linguistics-based safety evaluation platform for large language models[J]. arXiv Preprint, arXiv: 2311.00286, 2023. |
| [47] | LIU S, CUI S, BU H, et al. JailBench: a comprehensive Chinese security assessment benchmark for large language models[J]. arXiv Preprint, arXiv: 2502.18935, 2025. |
| [48] | QIU H, ZHANG S, LI A, et al. Latent jailbreak: a benchmark for evaluating text safety and output robustness of large language models[J]. arXiv Preprint, arXiv: 2307.08487, 2023. |
| [49] | JIN H, SHI J, XU H, et al. MedEthicEval: evaluating large language models based on Chinese medical ethics[J]. arXiv Preprint, arXiv: 2503.02374, 2025. |
| [50] | LIU X, ZHU Y, ZHU S, et al. Evaluating moral beliefs across LLMs through a pluralistic framework[J]. arXiv Preprint, arXiv: 2411.03665, 2024. |
| [51] | CHEN Y, ZHANG X, HUANG Y, et al. Beyond English: unveiling multilingual bias in LLM copyright compliance[J]. arXiv Preprint, arXiv: 2503. 05713, 2025. |
| [52] | JIN Z, KLEIMAN-WEINER M, PIATTI G, et al. Language model alignment in multilingual trolley problems[J]. arXiv Preprint, arXiv: 2407.02273, 2024. |
| [53] | LI M, CHEN M B, TANG B, et al. NewsBench: a systematic evaluation framework for assessing editorial capabilities of large language models in Chinese journalism[J]. arXiv Preprint, arXiv: 2403.00862, 2024. |
| [54] | ANANTAPRAYOON P, KANEKO M, OKAZAKI N. Evaluating gender bias of pre-trained language models in natural language inference by considering all labels[J]. arXiv Preprint, arXiv: 2309.09697, 2023. |
| [55] | CAO H, WANG Y, JING S, et al. SafeDialBench: a fine-grained safety benchmark for large language models in multi-turn dialogues with diverse jailbreak attacks[J]. arXiv Preprint, arXiv: 2502.11090, 2025. |
| [56] | ZHANG Z, LEI L, WU L, et al. SafetyBench: evaluating the safety of large language models[J]. arXiv Preprint, arXiv: 2309.07045, 2023. |
| [57] | LIU Y, ZHENG Y, XIA S, et al. SAFETY-J: evaluating safety with critique[J]. arXiv Preprint, arXiv: 2407. 17075, 2024. |
| [58] | SUN H, ZHANG Z, DENG J, et al. Safety assessment of Chinese large language models[J]. arXiv Preprint, arXiv: 2304.10436, 2023. |
| [59] | XU L, ZHAO K, ZHU L, et al. SC-Safety: a multi-round open-ended question adversarial safety benchmark for large language models in Chinese[J]. arXiv Preprint, arXiv: 2310.05818, 2023. |
| [60] | LI G, ZHANG Y, WANG Y, et al. PRIV-QA: privacy-preserving question answering for cloud large language models[J]. arXiv Preprint, arXiv: 2502. 13564, 2025. |
| [61] | YUAN X, LI J, WANG D, et al. S-Eval: automatic and adaptive test generation for benchmarking safety evaluation of large language models[J]. arXiv Preprint, arXiv: 2405.14191, 2024. |
| [62] | ZHANG Z, LU Y, MA J, et al. ShieldLM: empowering LLMs as aligned, customizable and explainable safety detectors[J]. arXiv Preprint, arXiv: 2402.16444, 2024. |
| [63] | XIE T, QI X, ZENG Y, et al. SORRY-Bench: systematically evaluating large language model safety refusal behaviors[J]. arXiv Preprint, arXiv: 2406.14598, 2024. |
| [64] | YUAN J, ZHANG J, WEN A, et al. The science of evaluating foundation models[J]. arXiv Preprint, arXiv: 2502.09670, 2025. |
| [65] | WANG W, TU Z, CHEN C, et al. All languages matter: on the multilingual safety of LLMs[J]. arXiv Preprint, arXiv: 2310.00905, 2023. |
| [66] | LI Y, WANG Y, CHANG Y, et al. XTRUST: on the multilingual trustworthiness of large language models[J]. arXiv Preprint, arXiv: 2409.15762, 2024. |
| [1] | NING Keyu, MA Fei, LI Zhe, DONG Xiaohui. A review of post-training cost optimization technology for large language models based on distributed computing optimization [J]. Information and Communications Technology and Policy, 2026, 52(2): 44-52. |
| [2] | WEI Tiancheng, GUO Zhen, YANG Yunlong. Research on the paths and strategies of empowering smart city construction with large language models [J]. Information and Communications Technology and Policy, 2025, 51(8): 91-96. |
| [3] | LIU Dongfang, YANG Tiankai, CHANG Zheng, HAO Pengfei. Mechanism innovation and practical exploration of large language models empowering government investment project evaluation [J]. Information and Communications Technology and Policy, 2025, 51(12): 48-56. |
| [4] | WANG Wei, PANG Xiaobo. Research on application strategies for government large models [J]. Information and Communications Technology and Policy, 2025, 51(11): 74-80. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
2020 © Information and Communications Technology and Policy
Address: 52 Huayuan North Road, Beijing, China Phone: 010-62300192 E-mail: ictp@caict.ac.cn