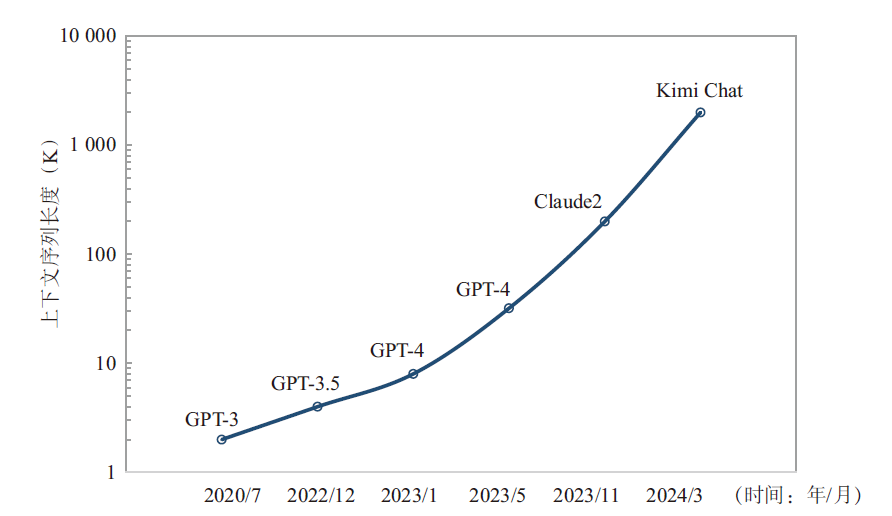
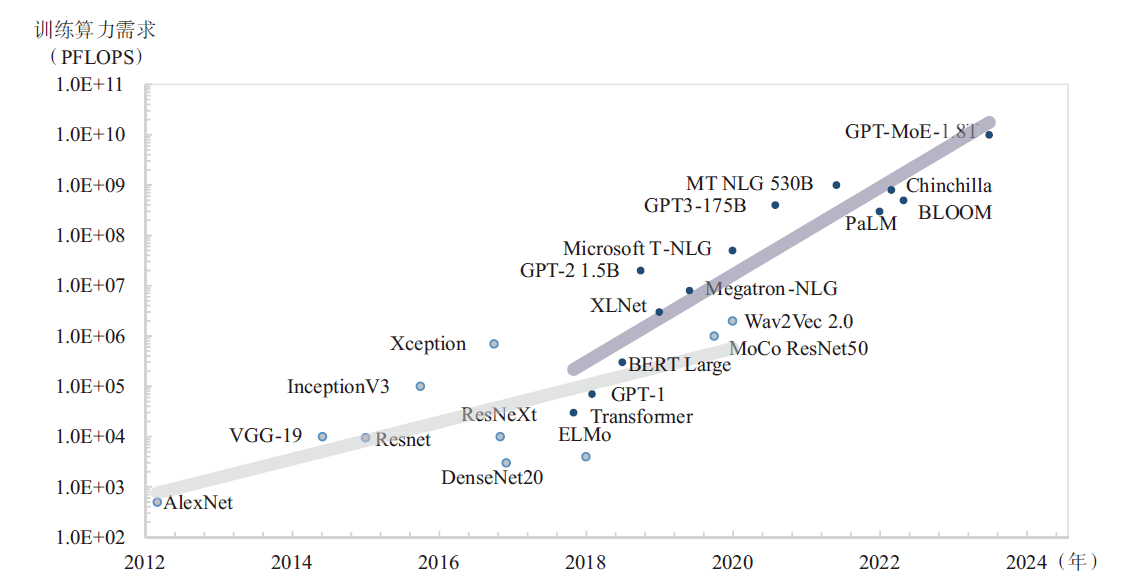
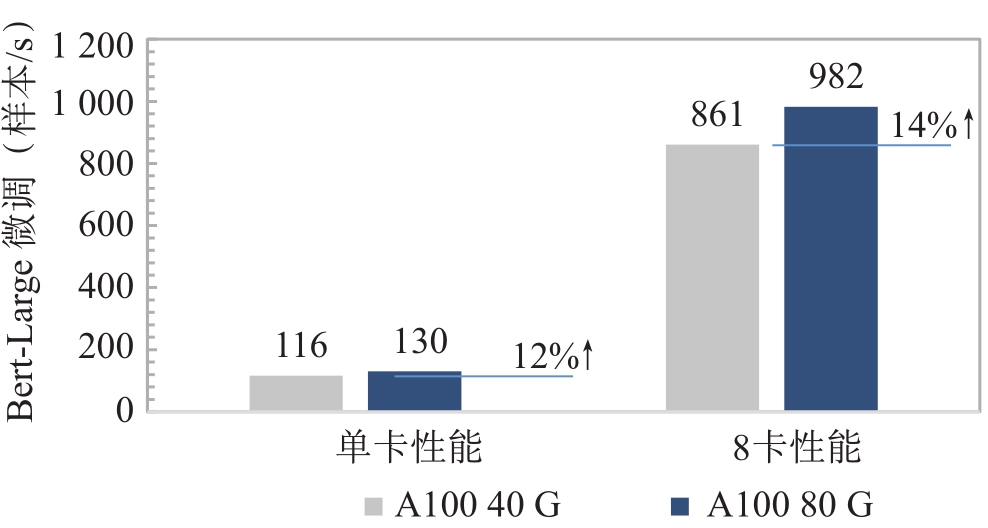
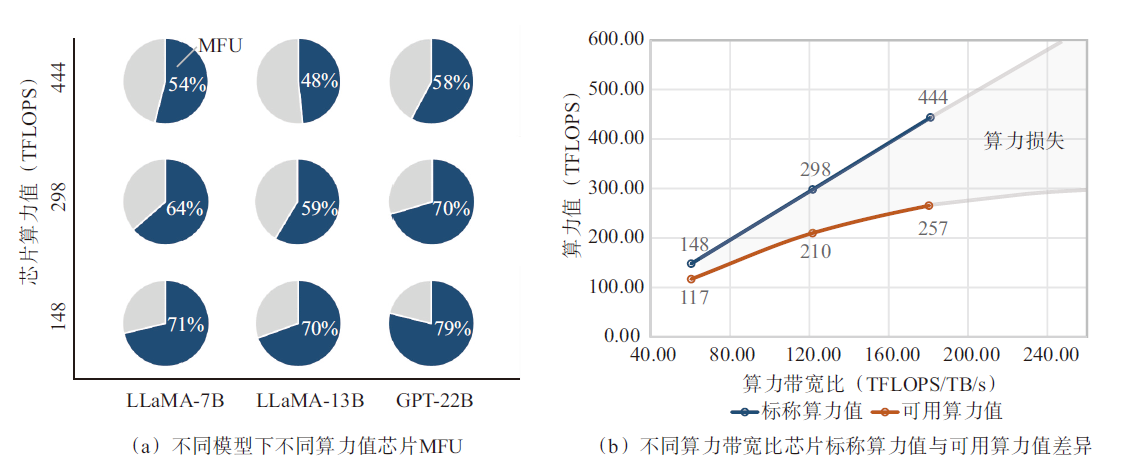
| [1] |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[J]. arXiv Preprint. arXiv:1706.03762, 2023. DOI:10.48550/arXiv.1706.03762.
|
| [2] |
DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[J]. arXiv Preprint. arXiv:1810.04805, 2018. DOI:10.48550/arXiv.1810.04805.
|
| [3] |
YEKTA M M J. The general intelligence of GPT-4, its knowledge diffusive and societal influences, and its governance[J]. Meta-Radiology, 2024, 2(2):20-37.
|
| [4] |
SUN C, MYERS A, VONDRICK C, et al. VideoBERT: a joint model for video and language representation learning[C]. Seoul: IEEE CVF International Conference on Computer Vision (ICCV), 2019:7463-7472. DOI:10.1109/ICCV.2019.00756.
|
| [5] |
KORTHIKANTI V, CASPER J, LYM S, et al. Reducing activation recomputation in large transformer models[J]. arXiv Preprint. arXiv:2205.05198, 2022. DOI:10.48550/arXiv.2205.05198.
|
| [6] |
FEDUS W, ZOPH B, SHAZEER N. Switch transformers: scaling to trillion parameter models with simple and efficient sparsity[J]. arXiv Preprint. arXiv:2101.03961, 2021. DOI:10.48550/arXiv.2101.03961.
|
| [7] |
TOUVRON H G, LAVRIL T, IZACARD G, et al. LLaMA: open and efficient foundation language models[J]. arXiv Preprint. arXiv:2302.13971, 2023. DOI: 10.48550/arXiv.2302.13971.
|
| [8] |
LIEBER O, LENZ B, BATA H, et al. Jamba: a hybrid transformer-mamba language model[J]. arXiv Preprint. arXiv:2403.19887, 2024.
|
| [9] |
LEPIKHIN D, LEE H J, XU Y, et al. GShard: scaling giant models with conditional computation and automatic sharding[J]. arXiv Preprint. arXiv:2006.16668, 2020. DOI:10.48550/arXiv.2006.16668.
|
| [10] |
PATEL D, WONG G. GPT-4architecture, infrastructure, training dataset, costs, vision, MoE[EB/OL]. (2023-07-10)[2024-04-20]. https://www.semianalysis.com/p/gpt-4-architecture-infrastructure.
|
| [11] |
GHOLAMI A, YAO Z, KIM S, et al. AI and memory wall[J/OL]. arXiv Preprint. arXiv:2403.14123v1, 2024. https://arxiv.org/html/2403.14123v1.
|
| [12] |
国家信息中心. 智能计算中心创新发展指南[Z], 2023.
|